





I have started thinking of where I would like to see glu go in the future (3 to 6 months timeframe). It seems to me that what makes the most sense for the evolution of glu is to embrace the cloud.
glu today…
Today glu works really well (at least I assume :) when the glu environment is setup: machines are up and running with a glu agent on it, ZooKeeper is installed, the console is up and running. The tutorial that comes with glu has streamlined this effort for a quick and easy demonstration when everything runs locally on the same machine. The production setup is a bit more involved and could also be made more streamlined (there are several tickets tracking this like #58 and #84).
In the end, glu is a deployment automation platform which allows you to automate the deployment of your applications and services on a set of nodes. The missing piece is that glu does not know how to provision itself. One of the challenge of course is that in order to provision glu, first you need a node. In many cases (and this is the case at LinkedIn), this step involves an actual human being who is going to rack a physical piece of hardware, then install the OS on it, etc…
One of the key concept of glu is that it turned provisioning into an API. Since it is an API, you can programmatically call it (which means you can programmatically provision a node) and of course you can automate it.
In my mind, one of the biggest gain that the cloud is bringing, is the fact that you can now treat hardware as software: you now have an API that allows you to bring machines up and down. This is a big mind shift. The beauty of it is since it is an API you can automate it!
glu in the cloud
At the heart of glu relies the model which defines what applications (services) need to run where. The where part is already pretty abstract but glu assumes that it is a node that is already glu aware.
Can we remove this assumption? After all, provisioning your applications is simply a matter of calling some API, and in the cloud, provisioning glu is also simply a matter of calling some API (albeit a very different one).
In this scenario we could envision that the model defines nodes in a more abstract way, for example: ec2:standard:XL/agent-1, which essentially defines agent-1 to be running on an extra large standard EC2 instance.
The same way that glu computes a delta to provision your applications, it could also determine that the node agent-1 does not exist and as a result, needs to be provisioned with glu, in which case it would use the EC2 apis to create a brand new VM and install what is necessary on the node for glu to run.
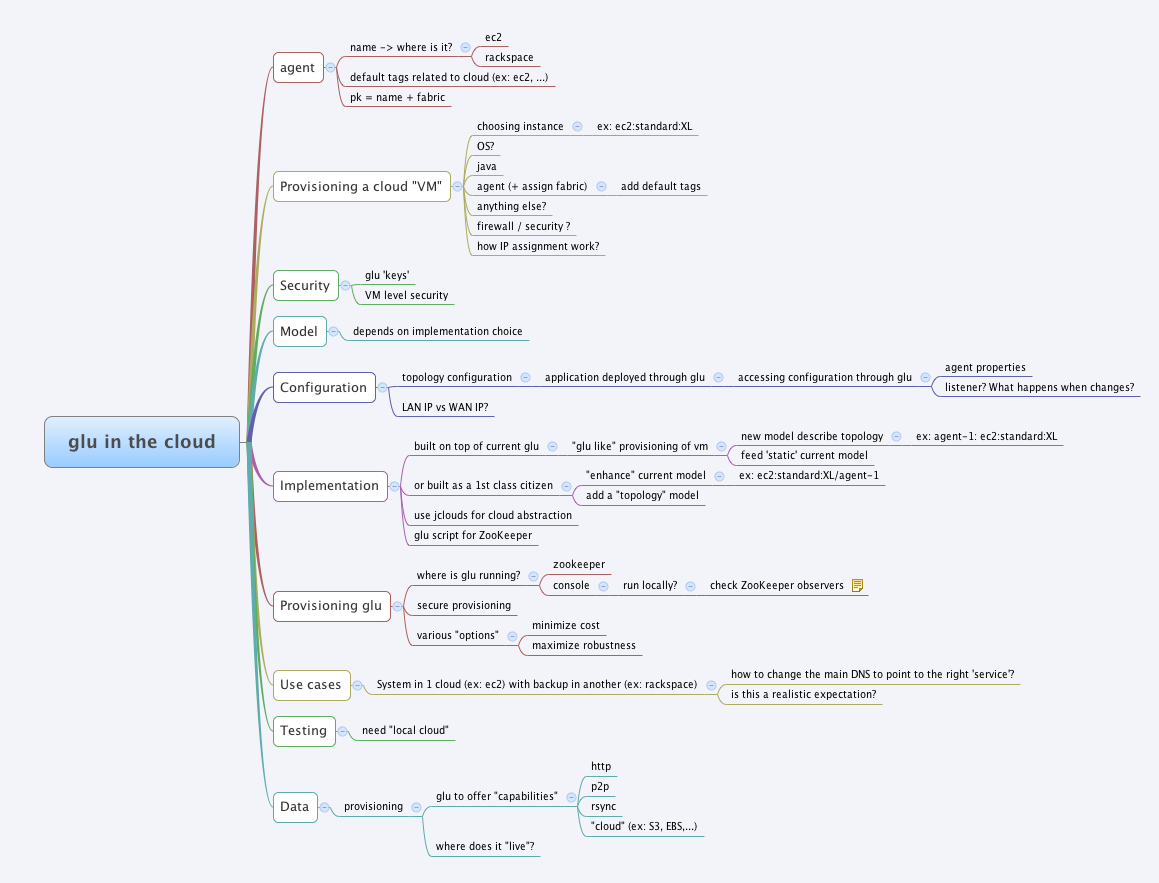
Mind map
In order to bootstrap the process I have created a mind map to capture my first thoughts (you can click the image to view the full version).
My dream
Currently I deploy my personal website kiwidoc on rackspace. The process is manual (this was done prior to glu and I did not port it). My dream is that I can use glu to deploy kiwidoc. And this is what I really want to be able to do: rackspace is having technical difficulties today… not a problem let’s switch to ec2 while it gets fixed. Dreaming is good :)
Joke aside, kiwidoc would be a fairly interesting use case. Although very small there are already a bunch of ‘issues’ that glu in the cloud would need to address. For example, kiwidoc is split amongst 2 machines (a nginx frontend and a tomcat backend). The frontend needs to talk to the backend and for that it needs to use the ‘internal’ IP so that it not counted as external traffic. Also kiwidoc uses data (which is not code), like the search (Lucene) index. What happens if the node hosting the backend (and hence the index) needs to be recreated?
Feedback
In the end, the community is what makes glu both successful and interesting. I am soliciting feedback. Please leave some. Even if it is just a simple idea or comment, it doesn’t matter. I would really like this process to be collaborative. I would love to be able to derive a roadmap and start implementing it. Feel free to leave feedback on the forum.